

60秒直出3D内容,纹理逼真,Meta最新3D Gen模型实现60倍速生成
60秒直出3D内容,纹理逼真,Meta最新3D Gen模型实现60倍速生成
【导读】Meta 的 GenAI 团队在最新研究中介绍了 Meta 3D Gen 模型:可以在不到 1 分钟的时间内从文本直接端到端生成 3D 资产。
在图像生成和视频生成这两个赛道上,大模型仅用了两年多的时间就卷得如火如荼。
即使是效果堪比 Sora 的 Gen-3、Luma 等模型发布,也很难引起曾经的轰动反应。
你可能会疑惑,AI 还能玩出新花样吗?
Meta 放出的最新研究告诉你——能!
不管是图像还是视频,即使能做出 3D 效果,终究只是二维空间中的像素组成的。
Meta 最近发布的 3D Gen 模型,则能实现 1 分钟内的端到端生成,从文本直出高质量 3D 资产。

不仅纹理清晰、形态逼真自然,而且生成速度比其他替代方案加快了 3-60 倍。
目前,模型还没有开放试用 API 以及相应的代码,官方消息中也没有透露下一步的发布时间。

只能看到官方 demo 但没法试用,已经让很多网友心痒难耐了。
「把这些可爱的小东西 3D 打印出来该有多好。」

但好在,Meta 放出了技术报告,让我们可以细致观摩一下技术原理。

论文地址:https://ai.meta.com/research/publications/meta-3d-gen/
Meta 3D Gen
在电影特效、AR/VR、视频游戏等领域中,创作 3D 内容是最耗时,也是最具挑战性的环节之一,需要很高的专业技能和陡峭的学习曲线。
这件事对人类困难,对 AI 来说也同样困难。
相比于图像、视频等形式,生产级的 3D 内容有更多方面的严格要求,不仅包括生成速度、艺术质量、分辨率,还包括 3D 网格的结构和拓扑质量、UV 图结构以及纹理清晰度。
此外,3D 生成还面临数据方面的挑战。
虽然有数十亿张图像和视频可供学习,但其中适合训练的 3D 内容量却少了 3~4 个数量级。因此,模型只能学习这些非 3D 的视觉内容,并从二维的观察中推断出三维信息。
3D Gen 模型则克服了这些困难,在领域内迈出了第一步。
模型最大的亮点在于支持基于物理的渲染(PBR,physically-based rendering),这对于在应用场景中实现 3D 资产的重新照明非常必要。
此外,经过专业艺术家的评估,3D Gen 在生成同等质量,甚至更优内容的同时,缩短了生成时间,提升了指令跟随性能。
生成出 3D 对象后,模型还支持对其纹理进行进一步的编辑和定制,20s 内即可完成。

方法
这种更加高效的优质生成,离不开模型 pipeline 的精心设计。
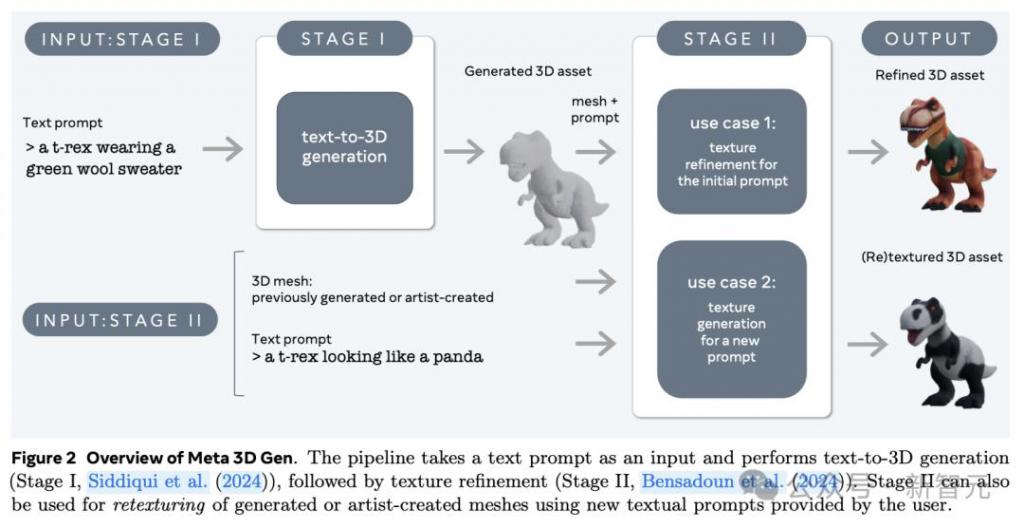
3D Gen 的生成主要分为两步,由两个组件分别完成——文本到 3D 对象生成器 AssetGen 和文本到纹理生成器 TextureGen。
第一阶段:3D 资产生成。根据用户提供的文本提示,使用 3D AssetGen 模型创建初始 3D 资产,即带有纹理和 PBR 材质图的 3D 网格,大约花费 30s。
第二阶段:纹理生成。根据第一阶段生成的 3D 资产和用户文本提示,使用 3D TextureGen 模型生成更高质量的纹理和 PBR 图,大约花费 20s。
其中,第二阶段的 TextureGen 也可以单独拿出来使用。如果有一个之前生成的,或者艺术家自己创作的无纹理 3D 网格,提供描述外观的文本提示后,模型也能在 20s 左右的时间中为它从头生成纹理。
AssetGen 和 TextureGen 这两个模型有效地结合了 3D 对象的三种高度互补的表示:视图空间(物体图像)、体积空间(3D 形状和外观)以及 UV 空间(纹理)。

AssetGen 项目地址:https://assetgen.github.io/
给定文本描述,AssetGen 首先利用一个多视角、多通道版本的图像生成器生成多张图像,随后生成物体的一致视图。
据此,AssetGen 中的重建网络在体积空间中提取出物体的初始版本,并进行网格提取,确立其 3D 形状和初始纹理。
最后,TextureGen 利用视图空间和 UV 空间的生成结果,对纹理进行重生成,在保持指令忠实度的同时提升纹理质量。

论文地址:https://ai.meta.com/research/publications/meta-3d-texturegen-fast-and-consistent-texture-generation-for-3d-objects/
上述的每一个阶段都是建立在 Meta 强大的文生图模型家族 Emu 之上,并使用了内部数据集进行微调,主要包括渲染过的合成 3D 数据。

单独使用 TextureGen 模型可以为同一个物体生成不同的纹理表面
不同于许多 SOTA 方法,AssetGen 和 TextureGen 都是前馈生成器,因此能实现快速、高效的部署。
将 3D 生成任务以这种方式划分为两个阶段,并在同一个模型中集成对象的多个表示空间,这种 pipeline 的组合是 Meta 重要的创新。
实验证明,不仅 AssetGen 和 TextureGen 两个部件都能分别取得更好的效果,它们结合后形成的 3D Gen 也能以 68% 的胜率超过其他模型。
实验
针对文本到 3D 资产生成的任务,论文将 3D Gen 与其他公开可用的常用方法进行了对比,并从用户调研、定性实验两个方面进行了评估。
定性结果
从生产结果上直观来看,3D Gen 能够应对不同范畴、不同类别物体的生成任务,而且指令跟随的忠实度甚至好过很多文生图模型。
比如让吉娃娃穿蓬蓬裙、让腊肠犬穿热狗装这样人类都很难想象的场景,3D Gen 也按照要求生成了合理的结果。

生成结果的多样性也非常惊艳。比如提示模型只生成 Llama(羊驼),他就能给出下图中的 13 种不同结果,风格、形状、纹理各异,可以说想象力很丰富了。

图 6、7、8 则对比了 3D Gen 和其他模型对同一文本提示的生成结果。
对于一些比较有挑战性的提示,3D Gen 的细节效果有时逊色于 Meshy v3 等模型,但这涉及到一个权衡问题:要展现纹理中的高频细节,代价就是有时会出现视觉失真。

下面这个多物体的复杂场景任务中,你觉得哪个模型的表现更好?

虽然成功的案例很多,但对目前的模型来说,翻车依旧时常发生,而且每个模型都有自己独特的翻法。
比如 CSM Cube 经常在物体几何上出问题,前后视角不一致,或者干脆生成了「双头大猩猩」;Tripo 3D 的光照效果会出现「一眼假」;Rodin Gen 1 和 Meshy 3.0 有时缺少物体细节的渲染。
至于 Meta 的 3D Gen,在放出来的案例中就出现了物体几何结构不完整、纹理接缝、指令不跟随(最右侧的海象没有叼烟斗)等多方面的问题。

虽然没人能在 Meta 的报告中战胜 Meta,但被拿来当「靶子」的作者,还是站出来为自己工作辩护了一番。

用户调研
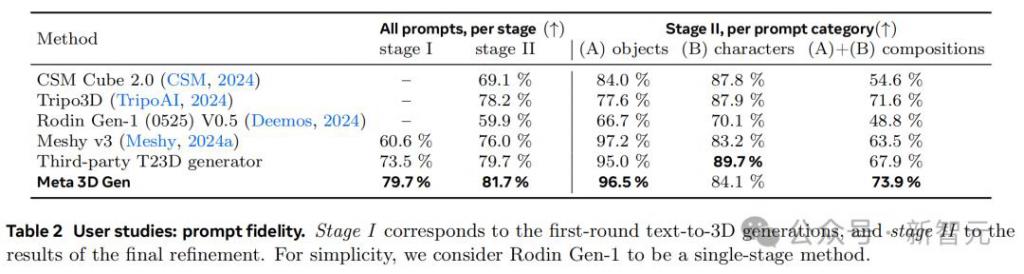
对于模型的文本到 3D 生成,人类评审将从两方面进行评估:提示忠实度、视觉质量。
按不同的背景,评审被分成了两组:(1)普通用户,没有 3D 方面的专业知识,(2)专业的 3D 艺术家、设计师和游戏开发者。
评估采用了 DreamFusion 引入的 404 个经过去重的文本提示,并根据内容复杂性分为三类:物体(156 个),角色(106 个)和物体角色组合(141 个)。
每个 3D 生成结果都会以 360 度全景视频的方式呈现给评审者,不同模型进行分别测试或者随机的 A/B 测试。
表 2 展示了提示忠实度方面的的评估结果。在这一指标上,3DGen 在两个阶段的得分都优于其他行业方法,紧随其后的是 T23D 生成器。
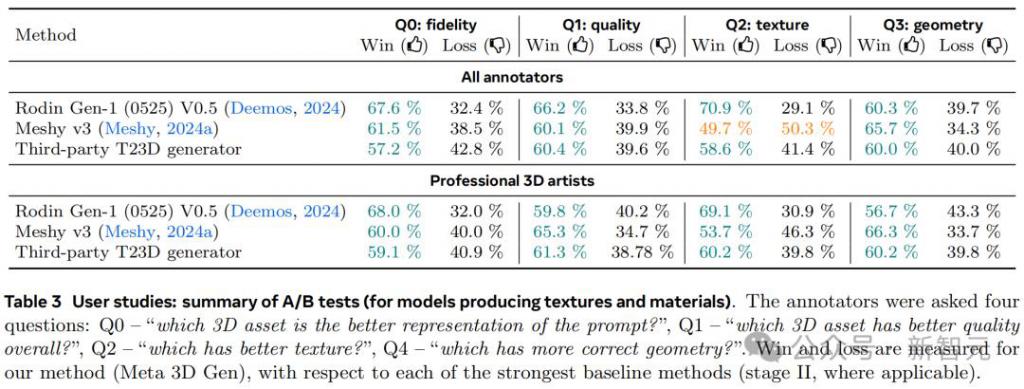
如表 3 所示,A/B 测试中还添加了对几何视觉质量以及纹理细节的评测。
作者发现,普通用户更倾向于喜欢那些纹理更锐利、生动、逼真且细节详实的 3D 结果,但对较明显的纹理和几何伪影不是很关注。专业的 3D 艺术家则会更重视几何与纹理的准确性。
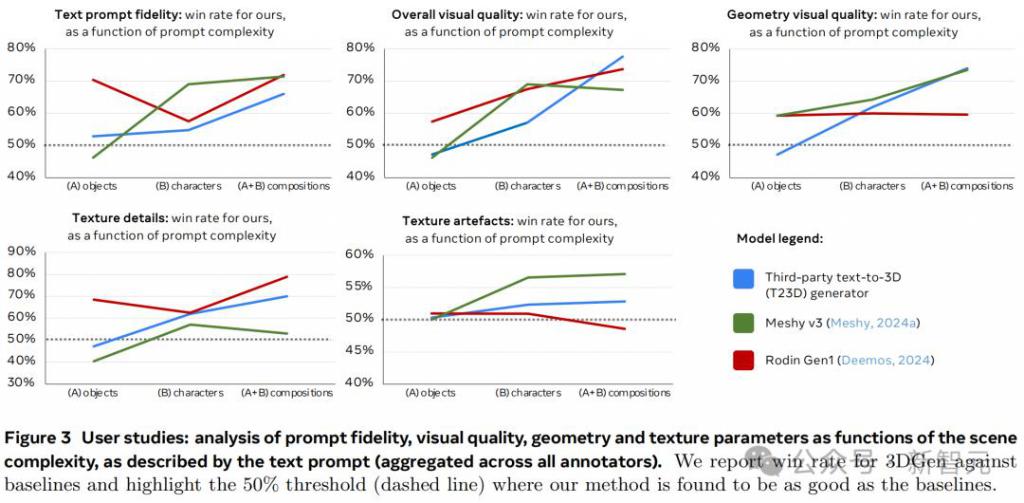
在图 3 中,作者分析了视觉质量、几何、纹理细节和纹理伪影的表现率等指标,如何随着文本提示描述的场景复杂度发生变化。
图表显示,虽然基准模型在简单提示下的表现与 3D Gen 相当,甚至更优,但随着提示复杂度逐渐增加,3D Gen 开始反超,这也与图 7 描述的定型结果一致。
结论
作为一个统一的流程,3DGen 整合了 Meta 的基础生成模型,用于文本到 3D 生成,具备纹理编辑和材料生成能力。
通过结合 AssetGen 和 TextureGen 的优势,3DGen 能够在不到一分钟的时间内根据文本提示生成高质量的 3D 对象。
在专业 3D 艺术家的评估中,3DGen 的输出在大多数情况下更受青睐,尤其是在复杂提示下,而且速度快 3 到 60 倍。
虽然 Meta 目前对 AssetGen 和 TextureGen 的整合比较直接,但它开创了一个非常有前景的研究方向,基于两个方面:(1)在视图空间和 UV 空间中的生成,(2)纹理和形状生成的端到端迭代。
如同 Sora 的出现会深刻影响短视频、电影、流媒体等众多行业一样,3D Gen 也具有同样巨大的潜力。
毕竟,小扎还是心心念念他的元宇宙。而 AI 驱动的 3D 生成,对于在元宇宙中构建无限大的虚拟世界也非常重要。
-

- 字节、腾讯争夺AI分发权
-
2024-07-05 03:21:42
-

- 东方甄选“失速”:网红模式与产品路线真的水火不容?
-
2024-07-05 03:19:26
-

- 从160万元降到39万元!天津武清一楼盘价格大跌背后
-
2024-07-05 03:17:10
-

- 阿里的“药”,难治家化的“病”
-
2024-07-05 03:14:54
-
- 女生退租遭辱骂致死案二审维持原判:房东赔19万元
-
2024-07-05 03:12:38
-
- 何小鹏要跟雷军争抢年轻人了
-
2024-07-05 03:10:22
-
- 低价电商无原罪,高价出不了Costco
-
2024-07-05 03:08:06
-

- 又一广州独角兽企业,“中国版ZARA”冲击IPO?
-
2024-07-05 03:05:50
-

- 又一著名京剧表演家因病逝世,享年79岁,曾因演唐僧一角走红
-
2024-07-04 06:13:53
-

- 养老保险缴纳比例
-
2024-07-04 06:11:37
-

- 养一叶莲老烂叶、不开花?
-
2024-07-04 06:09:21
-

- 月之暗面 Kimi 开放平台“上下文缓存”开启公测
-
2024-07-04 06:07:05
-

- 新疆伊犁5大美景盘点,每一处都美如“仙境”,有你喜欢的吗?
-
2024-07-04 06:04:49
-
- 行业揭秘:如何代理棋牌游戏-乐美棋牌游戏代理
-
2024-07-04 06:02:33
-

- 新疆四大美女,你觉得他们谁更美呢?
-
2024-07-04 06:00:18
-

- 印度西北边境告急,大批精锐越界发动袭击,东线印军被迫调转枪口
-
2024-07-04 05:58:02
-

- 又热又多雨!广州中考天气出炉
-
2024-07-04 05:55:46
-

- 有种身材叫郑爽的身材,看清楚无修图后,这还是你心中的女神吗?
-
2024-07-04 05:53:30
-

- 他把学生“盘中餐”当作“摇钱树” 为人师者却德不配位,最终自食恶果
-
2024-07-03 05:16:35
-

- 多所高校降低转专业门槛,如何实施?有何影响?
-
2024-07-03 05:14:19
 贵州两落马女厅官出镜忏悔:一人想念父母做的菜;一人带衣服投案
贵州两落马女厅官出镜忏悔:一人想念父母做的菜;一人带衣服投案 北京等地上空疑现不明飞行物!目击网友称“飞着飞着就没了”
北京等地上空疑现不明飞行物!目击网友称“飞着飞着就没了” 毛戈平7年IPO折戟,国货化妆品的出路在哪里
毛戈平7年IPO折戟,国货化妆品的出路在哪里 苹果Vision Pro,被华强北啃了
苹果Vision Pro,被华强北啃了 红薯原产地是哪个国家 红薯原产地是哪个国家或地区生产的
红薯原产地是哪个国家 红薯原产地是哪个国家或地区生产的 大模型浪潮不能使鬼推磨,但可以让周鸿祎、傅盛握手言和
大模型浪潮不能使鬼推磨,但可以让周鸿祎、傅盛握手言和 中产捧红的始祖鸟即将IPO,安踏捧出第二个“FILA”?
中产捧红的始祖鸟即将IPO,安踏捧出第二个“FILA”? 不想过年的年轻人,躲回工作中
不想过年的年轻人,躲回工作中 对伏是什么意思 伏的意思是什么
对伏是什么意思 伏的意思是什么 立冬补冬还是冬至补冬 立冬补冬什么意思
立冬补冬还是冬至补冬 立冬补冬什么意思