

震撼一夜!OpenAI首个AI视频模型炸裂登场,谷歌升级Gemini 1.5完爆GPT-4
震撼一夜!OpenAI首个AI视频模型炸裂登场,谷歌升级Gemini 1.5完爆GPT-4

人工智能(AI)行业又迎来了疯狂、震撼的一夜。
北京时间 2 月 16 日凌晨 2 点左右,美国 OpenAI 公司正式发布其首个文本 - 视频生成模型 Sora。
据悉,通过简短或详细的提示词描述,或一张静态图片,Sora 就能生成类似电影的逼真场景,涵盖多个角色、不同类型动作和背景细节等,最高能生成 1 分钟左右的 1080P 高清视频。
这是继 Runway、Pika、谷歌和 Meta 之后,OpenAI 正式加入到这场 AI 视频生成领域 " 战争 " 当中,同时也是 GPT、DALL · E 之后,2024 年 OpenAI 发布的旗下最新、最重要的 AI 产品系列。
OpenAI 强调,"Sora 是能够理解和模拟现实世界的模型的基础,我们相信这一功能将成为实现通用人工智能(AGI)的重要里程碑。"
更早之前,谷歌昨夜 23 点突然升级了 Gemini 系列模型,并发布用于早期测试的 Gemini 1.5 第一个版本—— Gemini 1.5 Pro,采用稀疏 MOE 架构,配备了 128000 个 token 上下文窗口,性能和长文本都超过了 GPT-4 Turbo。
从 Sora 到 Gemini,所有人都在感叹:行业真的变天了,AI 快要把人类 KO 了;好莱坞的时代真的要结束了?
OpenAI 视频生成模型 Sora 诞生:效果炸裂、现实不存在了
OpenAI 今晨公布的首个视频生成模型 Sora,采用一种名为扩散模型的技术(diffusion probabilistic models)。
而且,与 GPT 模型类似,Sora 也使用了 Transformer 架构,并完美继承 DALL · E 3 的画质和遵循指令能力,生成的视频一开始看起来像静态噪音,然后通过多个步骤去除噪音,逐步转换视频。
对于初学者来说,Sora 可以生成各种风格的视频(例如,真实感、动画、黑白),最长可达一分钟 —— 比大多数文本 - 视频模型要长得多。
这些视频保持了合理的连贯性。相比其他 AI 视频模型,Sora 视频生成质量好多了,更让人 " 舒服 " ——没有出现 " 人工智能怪异 " 类场景。
比如,AI 想象中的 " 龙年春节 ",Sora 能形成紧跟舞龙队伍抬头好奇的儿童,也能生成海量人物角色各种行为。

输入 prompt(提示词):一位 24 岁女性眨眼的极端特写,在魔法时刻站在马拉喀什,70 毫米拍摄的电影,景深,鲜艳的色彩,电影效果。

输入 prompt(提示词):一朵巨大、高耸的人形云笼罩着大地。云人向大地射出闪电。

输入 prompt(提示词):几只巨大的毛茸茸的猛犸象踏着白雪皑皑的草地走近,它们长长的毛茸茸的皮毛在风中轻轻飘动,远处覆盖着积雪的树木和雄伟的雪山,午后的阳光下有缕缕云彩,太阳高高地挂在空中距离产生温暖的光芒,低相机视角令人惊叹地捕捉到大型毛茸茸的哺乳动物,具有美丽的摄影和景深效果。

通过这些动图来看,Sora 不仅可以在单个视频中创建多个镜头,而且还可以依靠对语言的深入理解准确地解释提示词,保留角色和视觉风格。
当然,Sora 也存在一些弱点,OpenAI 表示,它可能难以准确模拟复杂场景的物理原理;可能无法理解因果关系;还可能混淆提示的空间细节;可能难以精确描述随着时间推移发生的事件,例如遵循特定的相机轨迹等。
但瑕不掩瑜,Sora 不仅能模拟真实世界,而且包括学习了摄影师和导演的表达手法,将 AI 视频惟妙惟肖地展现出来。
因此,Sora 已经成为了目前最强的 AI 视频生成类模型。
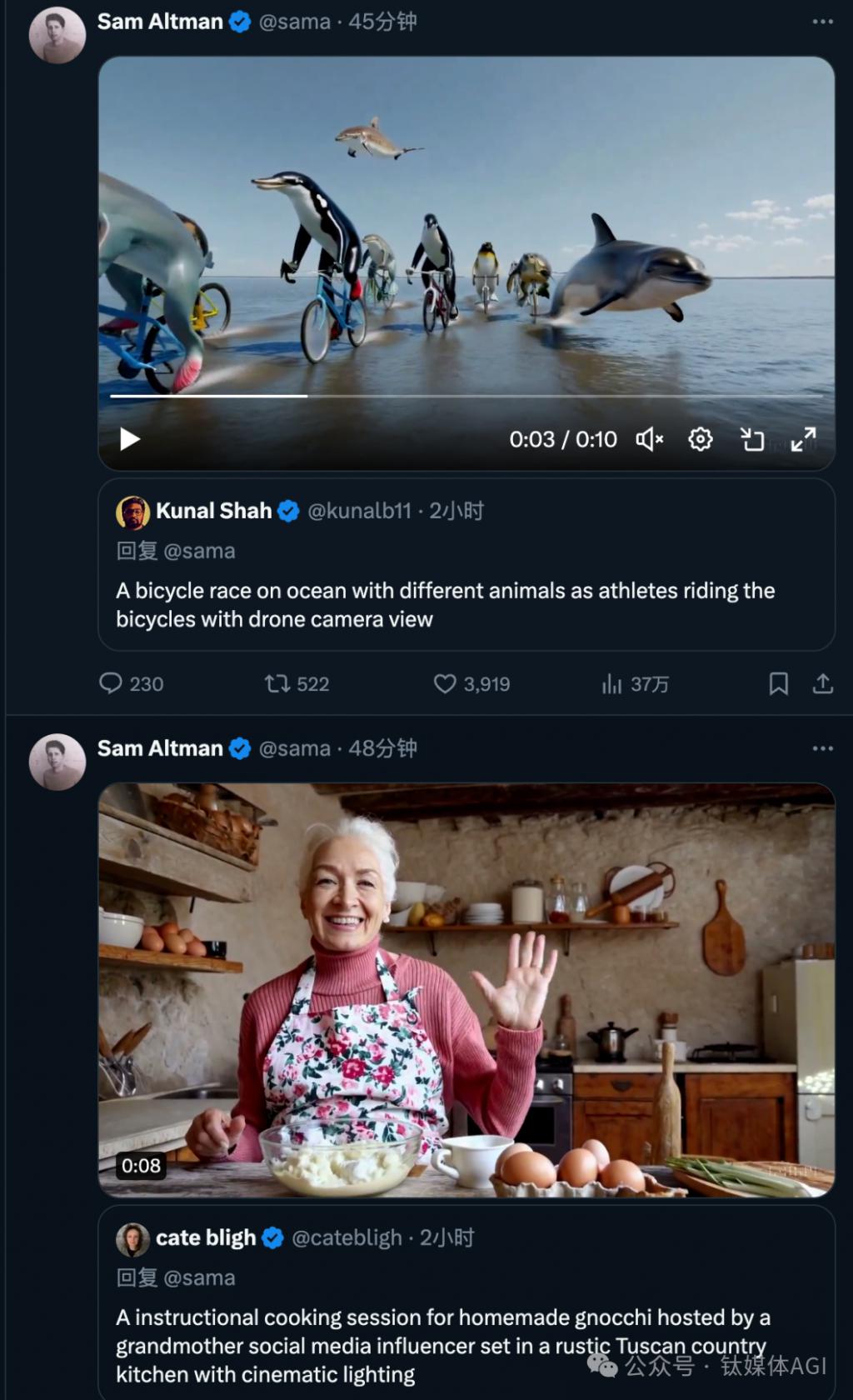
在社交平台上,已经有一些视觉艺术家、设计师和电影制作人(以及 OpenAI 员工)获得 Sora 访问权限。他们开始不断放出新的提示词,OpenAI CEO 奥尔特曼开始了 " 在线接单 " 模式。
带上提示词 @sama,你就有可能收到奥尔特曼 " 亲自发布 " 的 AI 视频回复。
截至发稿前,OpenAI 公布了更多关于 Sora 的技术细节。
技术报告显示,OpenAI 并不是把 Sora 单纯当做一个视频模型来看待:将视频生成模型作为 " 世界模拟器 ",不仅可以在不同设备的原生宽高比直接创建内容,而且展示了一些有趣的模拟能力,如 3D 一致性、长期一致性和对象持久性等。
" 我们探索视频数据生成模型的大规模训练。具体来说,我们在可变持续时间、分辨率和宽高比的视频和图像上联合训练文本条件扩散模型。我们利用对视频和图像潜在代码的时空补丁进行操作的 Transformer 架构。我们最大的模型 Sora 能够生成一分钟的高保真视频。我们的结果表明,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。"OpenAI 表示。

整体来看,Sora 生成的视频噪音比较少,原始的训练数据比较 " 干净 ",而且基于 ChatGPT、DALL · E 文生图技术能力,Sora 视频生成技术更加高超。
消息公布后,网友直呼,工作要丢了,视频素材行业要 RIP。
论文链接:https://shrtm.nu/sqr
谷歌 Gemini1.5 火速上线:MoE 架构,100 万上下文
除了 Sora 之外,今天凌晨,计划全面超越 GPT 的谷歌,宣布推出 Gemini 1.5。
Gemini 1.5 建立在谷歌基础模型开发和基础设施之上,采用包括通过全新稀疏专家混合 ( MoE ) 架构,第一个版本 Gemini 1.5 Pro 配备了 128000 个 token 上下文窗口,可推理 100,000 行代码,提供有用的解决方案、修改和注释使 Gemini 1.5 的训练和服务更加高效。
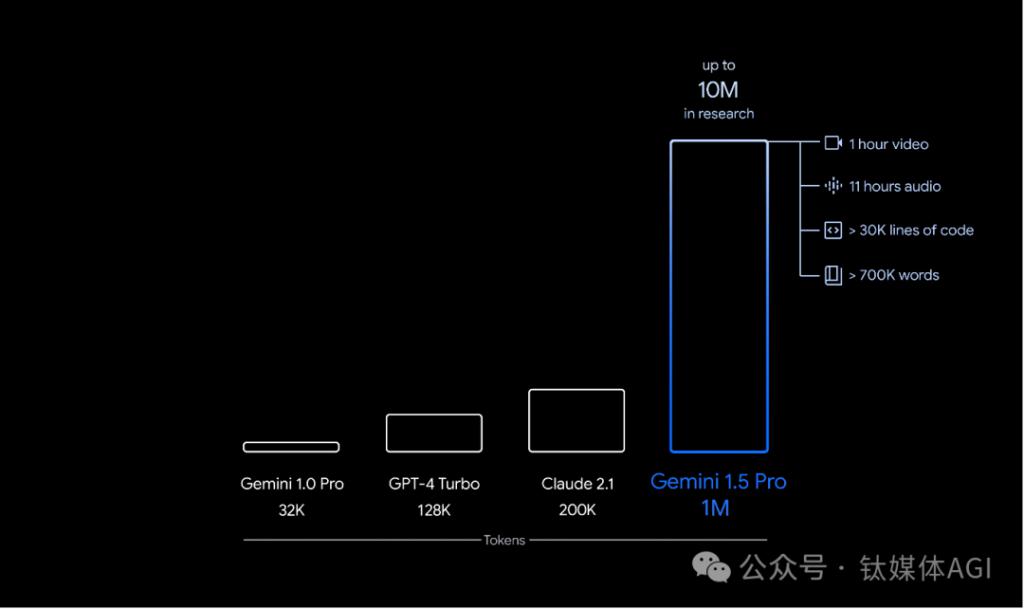
谷歌称,Gemini 1.5 Pro 性能水平与谷歌迄今为止最大的模型 1.0 Ultra 类似,并引入了长上下文理解方面的突破性实验特征,性能、文本长度均超越了 GPT-4 Turbo。
从今天开始,少数开发人员和企业客户可以通过 AI Studio 和 Vertex AI 的私人预览版在最多 100 万个 token 的上下文窗口中进行尝试 1.5 Pro 预览版。
谷歌表示,其致力于负责任地将每个新一代 Gemini 模型带给全球数十亿人、开发者和企业用户使用。未来,当模型进行更广泛的发布时,届时谷歌将推出具有标准 128,000 个 token 的 1.5 Pro 版本,甚至扩展到 100 万个 token 的定价等级。
One More Thing:AI 行业都 " 卷 " 起来了
有趣的是,截至发稿前,Meta 也公布了一种视频联合嵌入预测架构技术 V-JEPA。
这是一种通过观看视频教会机器理解和模拟物理世界的方法,V-JEPA 可以通过自己观看视频来学习,而不需要人类监督,也不需要对视频数据集进行标记,甚至根据一张静止图片来生成一个动态的视频。
与其他模型相比,V-JEPA 的灵活性使其在训练和样本效率上实现了 1.5 到 6 倍的提升。另外,在图像分类中,它可识别图像中的主要对象或场景;动作分类方面,它识别视频片段中的特定动作或活动;时空动作检测方面,可识别视频中动作的类型及其发生的具体时间和位置。
跑分方面,V-JEPA 在 Kinetics-400 达到了 82.0% 的准确率;Something-Something-v2 达到了 72.2% 的准确率;ImageNet1K 图像分类任务上达到了 77.9% 的准确率。
Meta 称,这是人工智能模型迈出的又一重要一步利用对世界的学习理解来计划、推理和完成复杂的任务。而且,V-JEPA 展示了 Meta 在通过视频理解推进机器智能方面的先进成就,为实现更高级的机器智能和人工通用智能(AGI)奠定基础。
总结来看,2024 年开年,AI 大模型技术进展全面加速,视频、图像、文本生成能力比一年前大大增强。
如果说,2023 年还是 "AI 图文生成元年 " 的话,今年,OpenAI 将推动行业进入 "AI 视频生成元年 "。
如果按照最近估值超过 800 亿美元的 OpenAI 公布新产品的速度来计算,GPT-5 将很快对外发布。
2 月初,被誉为 " 女版巴菲特 " 的方舟投资管理公司 CEO 凯茜 · 伍德(Cathie Wood)最新预测,AI 技术发展速度快于市场预期,AGI 最早将在 2026 年出现,最晚则到 2030 年出现。
(本文首发钛媒体 App,作者|林志佳)
-
- 巴菲特,跑了!
-
2024-02-16 15:38:19
-
- 蔡磊近况令人揪心,脑机接口等技术上新,“解冻”渐冻症,新希望在哪
-
2024-02-15 17:12:18
-

- 对话支付宝CTO:AI 行业全面“内卷”下,持续九年的五福节有哪些新技术落地?
-
2024-02-15 17:10:02
-

- 湖南所有高速恢复正常通行
-
2024-02-15 17:07:45
-

- 单张炒至10万块、收割全国小学生,这家卖奥特曼卡片的公司要上市了
-
2024-02-15 17:05:29
-
- 我在县城开零食店,春节能卖200万
-
2024-02-15 17:03:13
-

- 不想过年的年轻人,躲回工作中
-
2024-02-15 17:00:57
-

- 薇娅不再隐身
-
2024-02-15 16:58:41
-

- 龙年出生的企业家有什么特点
-
2024-02-15 16:56:25
-

- 今年春晚,终于不按套路出牌了!
-
2024-02-15 16:54:09
-

- 这个春节,他们在海外做短剧
-
2024-02-15 16:51:53
-

- 绿皮书:2023年我国家庭人均旅游花费较2020年增加31.3%
-
2024-02-15 12:54:51
-

- 曝光!“最后关头才击落……”
-
2024-02-15 12:52:35
-

- 乘客称在武汉天河机场被关飞机6小时呼吸困难,有人报警23次,南航回应
-
2024-02-15 12:50:19
-

- 云南昭通一大桥附近山体塌方?地处川滇两省之间,多方回应
-
2024-02-15 12:48:03
-
- 16名党员干部在矛盾化解中作风不实、履职不力,被追责问责
-
2024-02-15 12:45:47
-

- 2024年春节假期出游,广东官方安全提示来了
-
2024-02-15 12:43:31
-

- 锂金属电池如何简单提高循环寿命?耗尽电量静置几个小时即可
-
2024-02-15 12:41:15
-
- 苹果推“AI 设计师”Keyframer:听你指挥,把图片变为动画
-
2024-02-15 12:39:00
-

- 社科院报告:我国地方志编修首次完成省市县三级全覆盖
-
2024-02-15 12:36:44
 苹果Vision Pro,被华强北啃了
苹果Vision Pro,被华强北啃了 北京等地上空疑现不明飞行物!目击网友称“飞着飞着就没了”
北京等地上空疑现不明飞行物!目击网友称“飞着飞着就没了” 2831人考试2093人次替考!广州开放大学分管副校长解聘
2831人考试2093人次替考!广州开放大学分管副校长解聘 毛戈平7年IPO折戟,国货化妆品的出路在哪里
毛戈平7年IPO折戟,国货化妆品的出路在哪里 大模型浪潮不能使鬼推磨,但可以让周鸿祎、傅盛握手言和
大模型浪潮不能使鬼推磨,但可以让周鸿祎、傅盛握手言和 中产捧红的始祖鸟即将IPO,安踏捧出第二个“FILA”?
中产捧红的始祖鸟即将IPO,安踏捧出第二个“FILA”? 荣耀赵明:Magic6要在体验上超越iPhone而不是参数上
荣耀赵明:Magic6要在体验上超越iPhone而不是参数上 嘉行传媒还“行”不“行”?
嘉行传媒还“行”不“行”? 尼罗河在哪个国家地图上 尼罗河是什么国家的
尼罗河在哪个国家地图上 尼罗河是什么国家的