

Sora负责人揭秘技术探索之路:成功的研究者,往往没有经过传统的研究训练
Sora负责人揭秘技术探索之路:成功的研究者,往往没有经过传统的研究训练
整理|周鑫雨 王奕昕
文|周鑫雨
编辑|邓咏仪
2024 年 1 月,Sora 炸场,多模态赛道则迎来了真正的春天。
OpenAI 发布的视频模型 Sora,不仅将视频生成长度的天花板从 10 秒抬高到了 60 秒,还让 AI 行业从大炼大语言模型,进入到新阶段:通过原生的多模态模型(而非多个单模态模型拼接),加速探索通往 AGI(通用人工智能)的可能性。
在 2024 年的智源大会上,智源研究院不仅发布了可以生成和理解视频的原生多模态模型 Emu3,还请来了两位 Sora 暴风眼中的人物:
Aditya Ramesh,OpenAI 的多模态扛把子,图像生成模型 DALL · E 之父,同时也是 Sora 的团队负责人之一。
在 2024 年 4 月的播客访谈中,他提出,像 Sora 这样的模型是实现 AGI 的关键步骤,因为能够模拟复杂的环境和世界。
谢赛宁,纽约大学计算机科学助理教授。他和 OpenAI Sora 的另一位核心成员 William Peebles(昵称 Bill),开创性地将 Transformer 与扩散模型结合,其研究成果 DiT,也成为了 Sora 的核心架构。
在以 " 生成建模如何发展 " 的讨论中,Aditya Ramesh 梳理了从 DALLE · 1 到 Sora 的视觉生成技术探索路径。
他提到,视觉生成已经经历了手动打标签、理解语言和图像的映射、从视觉中建构自然语言、从自然语言中构建视觉 4 个阶段。而下一阶段,则是让自然语言去建构一切模态。

△ Sora 负责人 Aditya Ramesh 与谢赛宁对谈现场 图源:智源研究院
在和谢赛宁的交流中,两人探讨了 DiT 架构对视觉建模的价值、通往 AGI 需要的人才、视频生成模型的应用,以及视频生成模型的训练数据来源。其中的观点有:
语言是一切模型的支架,理论上可以训练任何模态的模型。随着参数规模的增大,模型对语言的依赖程度会降低,并且开始学会自己解决问题。
纳入在校生人才,是 OpenAI 的招聘策略。OpenAI 更关注有潜力但还没获得正式学术成绩的人才,很多成功的研究者并没有经过传统研究的正式培训。同时,给人才充足的 GPU,是很重要的!!
若是能够提高可控性,并且灵活使用现有场景中的角色、资产和其他元素,视频生成模型很有可能会成为用户界面的游戏改变者。
现有来自互联网的数据可能已经让我们走得很远了。通过通过继续扩大模型规模,一旦模型强大到成为独立的世界模拟器,你就可以开始在视频生成模型内部进行接触、模拟等操作
以下是 Aditya Ramesh 和谢赛宁的对话实录,经《智能涌现》整理编辑:
谢赛宁:我在你的 X 账号中看到了一句话:" 语言模型被高估了。" 作为视觉研究出身的人,我真的很喜欢这个说法。但你认为视觉生成是通往 AGI 的关键道路吗?你如何看待建模人类语言与建模包含丰富感官数据的现实世界之间的关系?
Aditya Ramesh:我对此很坚信。在任何给定的视频中,你都可以获取很多信息,并且视频中的很多信息用语言很难表示。例如,我谈到了雷门的渐进矩阵,从视觉中学习到的智能类型,很难仅仅通过学习语言来建模。
所以我认为,语言将是更高阶的智能系统的重要组成部分,可以推理事物。但在某一时刻,我认为语言会被纳入视觉,这是一种更通用的界面。
谢赛宁:你提到,语言可以成为实现智能的框架。为了弥补视觉表现的不足,语言确实提供了非常多的先验知识。那么语言会成为一种捷径吗?你对此有什么想法吗?
Aditya Ramesh:我所期望的是,当你用强描述性的文本训练文生图模型时,它没有太多需要学习的东西。但是我们在 DALL · E 3 中看到的是,当在真正的描述性文本以及一些短文本上训练模型时,短文本训练的模型的性能会因为在更具描述性的文本上训练而提高。
因此,也许我们可以使用语言来训练生成模型,并帮助它们更有效地训练。但是随着参数规模的扩大,模型对语言作为条件信息的依赖程度将会降低,并且可以开始自行解决问题。
谢赛宁:我想聊聊 Sora 背后的天才。Bill(Sora 其中一位负责人)在博士的最后一年和我一起研究 DiT,而 Tim(Sora 其中一位负责人)在伯克利攻读博士学位期间一直致力于长视频生成。这两位刚刚获得博士学位,就能对这个领域产生如此大的影响,这真是太了不起了。
OpenAI 的团队文化是怎么支持年轻研究院发挥他们的热情、过去的经验,为团队做贡献?
Aditya Ramesh:OpenAI 的招聘策略与其他组织非常不同。当然,Tim 和 Bill 在加入 OpenAI 之前拥有博士学位和相当强的成果发表,但我们更关注那些有高潜力,但可能还没机会获得正式学术成绩的人,例如,James Becker,DALL · E 3 的负责人之一,他帮助将音频功能嵌入 GPT-4o。他是一个很好的例子。
其次,我们专注于拥有一个长期的研究目标,而不会受到领域进展的影响。也就是说,我们设定了一个足够遥远的目标,我们可以完全专注于此,而不是对每天变化的事件做出反应。
最后,我认为让每个人拥有充足的 GPU 很重要。

谢赛宁:我还注意到,和 OpenAI 一样,有很多非常成功的研究人员并没有真正经历所谓的传统研究、正式的研究培训。就像现在高等教育的作用一样,你认为博士学位也被高估了吗?你有给想在 AI 从事职业的下一代研究人员的建议吗?
Aditya Ramesh:我认为,我们现在通过 Transformer 统一了可扩展的计算范式,也知道如何表征数据,技术正在趋同。
我认为,它会改变你在学术界追求的项目的焦点,比如可解释性是我们追求的一个方向。我认为现在攻读博士学位并期望获得最先进的成果是很困难的,因为所需的资源比以前高得多。
谢赛宁:我知道你们有一个研究访问计划,可以为学术界提供一些学分,用于 LLM 和多模型学习的研究。我认为在工业界和学术界之间建立这种类型的合作伙伴关系的机会很多。
很多人对 Sora 也感到非常兴奋,我们也非常喜欢你在社交媒体上分享的视频。但问题是我们仍然无法访问它。你可能已经看到了最近发布的一些同类产品,比如短视频公司快手的 Kling,还有 Luma AI 的 Dream Machine。所以我想听听你的想法,你如何看待视频生成领域的竞争?以及有没有 Sora 的最新消息?
Aditya Ramesh:我认为像 Sora 一样强大的视频生成系统,我们最关心的主要是安全以及它对社会的影响。我们要小心确保当我们发布像 Sora 这样的模型时,人们不会把它用于虚假信息的生成和传播,同时模型的行为方式也要符合人们的期望。
总的来说,有竞争是很好的。很高兴看到其他实验室和公司也发布视频生成模型。我认为大量的人用不同的方法工作,会激发创造力。
回想起 DALL · E 2 的研究时期,当时 Google Brain 和 OpenAI 实验室轮番发表论文,推动扩散模型的最先进技术的发展。例如,Profful 和 Alex 撰写了论文《扩散模型在图像合成上超越 GANs》,并给出了分类器指引,接着 Jonathan Ho 和其他人又发布了无分类器的指引。
谢赛宁:最近我参加了纽约的 AI 电影节。我问所有的艺术家和电影导演一个问题:你真正需要的视频生成模型的一个特征是什么?令人惊讶的是,他们的答案都是一样的:更好的可控性。
我想知道这是否是 Sora 在下一个版本中也会关注的事情?通过和不同的艺术家合作,你学到了什么吗?语言会成为创意世界更好可控性的终极媒体界面吗?
Aditya Ramesh:我认为更好的可控性和减少随机性是我们从合作者那里得到的头号功能请求。我认为能够做到这一点,并重用以前场景中的角色、资产和其他元素将是一个重大变革。仅仅这一点,就能使视频生成模型在生产环境中变得有用。我觉得这有点有趣,因为在 DALL · E 1 的早期,我们就看到了上下文学习能力的出现,现在这些能力正在投入生产。
谢赛宁:我想问一些关于数据的问题。因为我知道很多 Sora 使用的数据来自互联网视频。为了通往 AGI,像现在这样的互联网视频足以支持这个目标吗?还是说我们需要发现新的数据源,甚至需要不同的感官媒介来帮助实现这个目标?
Aditya Ramesh:我认为现有的数据可能已经让我们走得很远了。我认为,我们可以通过扩大模型规模,来继续取得很大进展。
一旦模型强大到成为独立的世界模拟器,就会发生很多有趣的事情,你就可以开始在视频生成模型内部进行接触、模拟等操作。这样我们就可以开始融合现实世界环境的所有多样化和有趣的约束,并开始学习有趣的东西。
以下是 Aditya Ramesh 关于视频生成建模技术路径探索的分享,内容经《智能涌现》整理编辑:
Aditya Ramesh:嗨,很荣幸能在这里演讲,我是 OpenAI 视频生成的负责人。今天我想谈谈谈对于过去几年生成建模如何发展的观察,以及我认为事情会走向何方。
我想先谈谈一个相当古老的结果,至少在深度学习方面是这样。在 2021 年 1 月,我们发布了一篇关于 DALL · E 1 的博客文章,这是一个大规模的自回归 Transformer 模型,至少在当时是这样,它是在文本和量化图像上联合训练的。
我们决定这样做的原因,是因为我们看到了 Transformer 建模语言的初步生命迹象,我们想知道同样的技术是否可以扩展到其他模式的建模。它最终工作得很好,该模型能够输入文字,并将其转换为量化的图像补丁。
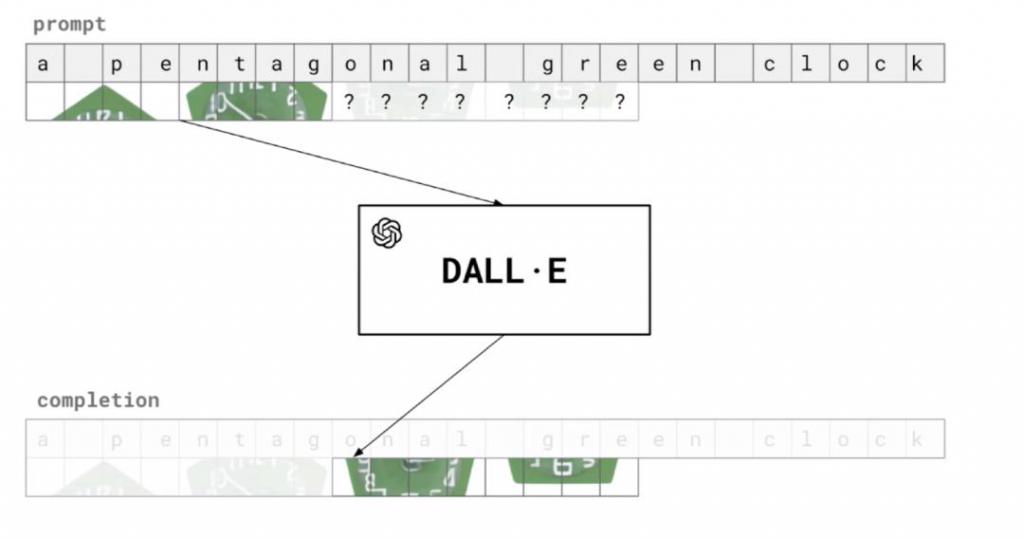
图源:智源大会直播截图
它的工作方式是给定一个语言 Prompt,您的建模就像通用的语言模型一样对其进行建模。我们还为图像训练了一个 VQ-VAE 编码器,图像块的嵌入会被语言的嵌入增强。
很酷的是,我们看到了 DALL · E 的规模增加,就像我们今天看到的语言模型规模增加一样。如果你训练一个小规模的自回归图像模型,你可以看到生成的图片中出现了光照和反射、重复的物体,以及小规模给事物上色的能力。
接着,在我们训练的稍微大规模的模型中,就可以绘制具有多个属性的对象、改变艺术风格等等。一旦规模再次过大,就可以看到文本渲染、组合泛化以及图像上下文学习的迹象。
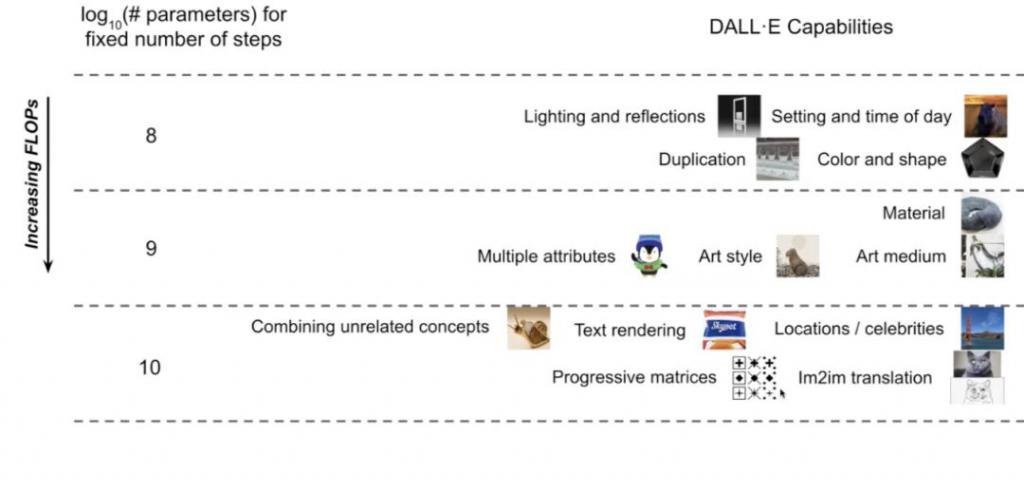
所以我们试着做一些事情,比如对 DALL · E 进行雷文渐进式推理矩阵测试 ( Raven ’ s Progressive Matrices Test ) ,这是一种视觉智商测试,模型看到网格中的前八个元素,必须填写最后一个角落。我们还尝试了图像到图像的转换,给模型一张图像的上半部分,要求它绘制下半部分。当模型参数规模达到十亿后,测试的结果开始转好。
我们想知道,如果进一步扩大规模会发生什么?
在 DALL · E 之后,我在想:这是学习智能的好方法吗?因为你正在训练一个模型来压缩视觉世界中的所有像素。这似乎是一项相当困难的任务,有很多信息需要建模。
当时有一些研究表明,这并不是正确的选择。Mark Chen 之前训练了 iGPT,这是第一个关于图像的自回归 Transformer 大模型。有趣的是,仅仅通过学习有效地压缩图像,模型就可以学习视觉世界的底层结构,并最终获得良好的图像表现。例如,当增加 iGPT 模型的参数规模时,它在 ImageNet 数据库探针上获得良好的结果。
然而,这比与 DALL · E 1 同期发布的 CLIP 效率低得多。CLIP 背后的想法是学习文本 - 图像数据集之间的共有信息。你想象一个带有文本和图像的维恩图,CLIP 使用对比损失来尝试学习数据集之间的共有信息。这最终比 iGPT 更有效地从图像中获取信息。
所以当时我得出结论:DALL · E 1 是一个有趣的项目,但这并不是从视觉世界中提取智能,并通往 AGI 的关键路径。
现在我将稍微谈谈 CLIP 如何提取文本 - 图像数据集之间的共有信息。CLIP 包含一个图像编码器和一个文本编码器:文本编码器接收文本 Prompt,图像编码器接收图像。
在训练期间,CLIP 模型会得到一个 " 图像 - 描述文本 " 数据对列表作为训练数据。文本编码器编码所有描述文本,图像编码器编码所有图像,最后对比损失优化,两个编码器从而对齐每个数据对的表征。
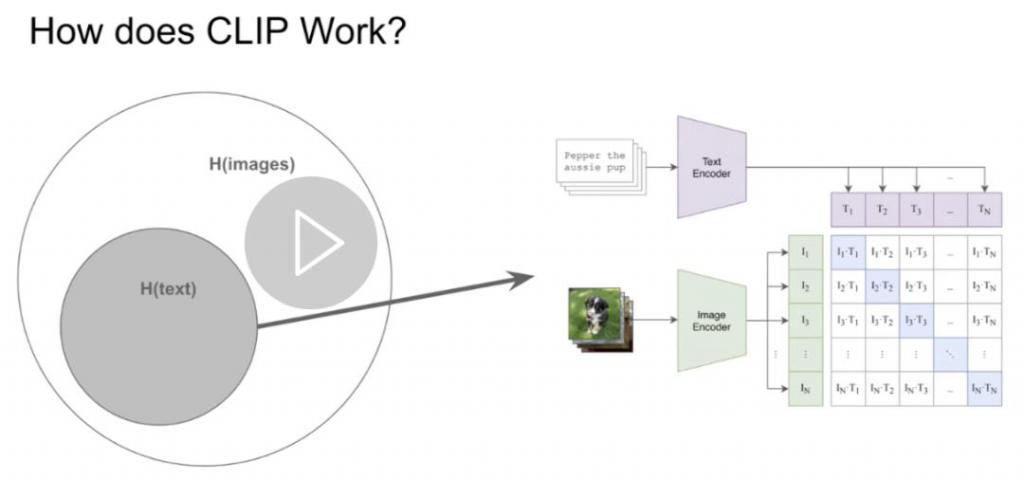
CLIP 的发布带来了巨大的范式转变,因为我们不用手动标注,而是可以利用互联网上的自由格式文本,来学习一个适用于所有领域的优秀分类器。
比如你想对动物进行分类,你可以为你想分类的动物类别构建一个 Prompt 列表,然后将想要分类的图像的嵌入与列表中的所有文本描述做点乘,您想对所有标题进行分类,然后取该点积的 Softmax 分数的最大值对应的类别作为分类结果。
从那时起," 图像表示学习 " 领域开始发展。在早期,分类模型只是从图像中提取一些信息,即图像所属类别的标签。多年后,CLIP 出现了,现在我们可以直接利用互联网上的文本来学习通用分类模型。紧接着,图像捕捉器也成了可扩展的视觉学习器。
因此,与其使用对比损失来建模文本和图像数据集的共有信息,我们可以训练一个具有图像编码器的感知模型,利用视觉信息重建自然语言,就像语言模型一样。

看起来,随着时间的推移,视觉建模变得越来越简单。我们的问题是:随着算力预算的增加,图像表示学习最终形态会是怎样?
iGPT 的启示是,大规模参数的生成模型能够自动学习数据的底层结构,并最终产生良好的图像表示。
那么 " 文本 - 图像 " 模型是否也有类似的结果?事实上确实如此。
不久前发表的一篇名为 "Your Diffusion Model is Secretly a Zero-Shot Classifier" 的论文的基本思想是,即使对给定文本描述的图像进行建模,该模型也可以转换为分类模型。它的工作方式与给定图像和描述文本的 CLIP 并没有太大的不同,你可以使用扩散模型来计算图像与文本匹配程度的分数,只是衡量图文数据相似度的函数更为复杂。
这篇论文表明,实际上稳定的扩散模型,能够获得良好的 ImageNet 探针测试结果。
这是一个令人惊讶的结果。这样一来,我们就可以从以图像为条件预测标签的训练范式,转向以文本为条件预测图像的训练范式。但是目前还不清楚这是否有效,或者我们需要额外花费多少计算量来完成任务。
训练 DALL · E 3 时,我们发现,当训练文本更具描述性时,训练 " 文生图 " 生成模型的效率也会变得更高。即便文本很短,只要具有很强的描述性,训练效果也很好。这表明,我们可以使用强描述性文本作为训练框架来训练更好的无条件模型。

如图所示,第一列的图像添加了不同程度的噪声,这些噪声表示建模图像的不确定信息。右边一列代表描述图片的最简单文本,比如只是描述图像中每个像素的颜色。
假设基于这些图像训练一个文生图模型,由于我们可以用文本描述每个像素,所以图像没有任何的不确定性,不需要深度学习模型。假设在图像中加入一点噪声,比如去掉一些表面细节和纹理,现在就有了一些不确定性,模型需要学习的东西不多,剩余的不确定性可以用一个强描述性的文本来描述。
假设你给图像添加大量噪声,就会存在很多不确定性。解释图像的剩余部分只需要简短的描述。当图像被添加成为纯噪声,就没有文本可以描述剩下的图像,此时任何图像都有可能。
如果一个模型只是在学习将像素值转换为图像,它可能并没有真正学到任何有用的东西。如果你有更多的算力,那么你可以训练一个将真正描述性的图像、真正描述性的文本翻译成图像的模型。直觉上,它可能没有学到很多东西,因为你给它的标题是如此的描述性,以至于图像中没有太多的不确定性可以让它学习。如果算力更多,你可以期待这个模型可以使用更短的文字,建模没有任何条件下的图像的熵。
我们认为,利用高描述性文本训练,有助于在小规模模型上补充感知相关的先验。这意味着我们可以从基于描述性文本的训练,转移到短文本的训练,即便在小参数规模下,当你给它描述性字幕时,它仍然可以是一个好的图像生成模型。当参数量较大时,它可以学习无法用语言轻松描述的只是,并在某种程度上填补剩余的空白部分。
这表明,我们可以从训练给定图像的文本模型,切换到训练给定文本的图像模型,而且不会对计算效率造成太大的影响。如果你在描述性文本上扩大模型参数,无条件建模任务的性能也会提高。

在整个探索过程中,最初我们并没有频繁使用文本,只是预测一些信息来训练图像分类器。然后我们开始在训练 CLIP 等图生文模型的过程中,更多地使用文本。最终我们可以通过使用高描述性的文本来训练优秀的生成模型,比如 DALL · E 3 和 Sora。最终,随着我们进一步扩展,也许语言会成为后续可以丢弃的框架,视觉世界可能是一个比文本更通用的界面。
接下来,我将谈谈当我们遵循这个范式时会发生什么。我们最初从图像建模文本开始,现在我们从文本建模图像。随着我们不断增加计算,语言的作用似乎正在被纳入视觉。
我们在 DALL · E 1 上也看到了一些有趣的东西,你可以做一些有趣的风格转移。你拿一张图片,然后使用 CLIP 嵌入的算法来改变图片的一些细节。
通过足够参数规模的视觉上下文学习,我们在 DALL · E 1 上看到了一些 " 生命 " 迹象。比如,给模型一个图像的上半部分,并要求它绘制图像的下半部分,并对图像的上半部分进行一些更改。这个模型从来没有被明确训练来完成这样的任务,但在足够的参数规模下,它最终还是学会了这一点。我们感觉这可能是通往各种视觉处理任务的通用界面的途径。

现在,我们开始训练出可靠的视频生成模型。在未来,也许我们可以向模型展示我们所拥有的图片,并要求它生成视频以达到我们想要的效果。
这就是我的简单观察。学习压缩一切可能是正确的方法,而语言只是使其实用的必要框架。但这还不够。我们需要其他技巧来重建我们看到的一切,以此有效地训练视频模型。语言会帮助我们到达那里,并最终被纳入视觉智能。最终,这将为我们提供一个非常通用的界面,用于模拟我们想要的任何东西。

欢迎交流!
-

- 内心阴暗的人有什么特征?
-
2024-06-17 19:30:29
-

- 一个东北小城的夏天:“比基尼之都”遭遇的危与机
-
2024-06-17 19:28:13
-

- 拿破仑最初自认为是外国人,在战争中赢得威信夺得政权并进行改革
-
2024-06-17 19:25:57
-

- 地下打黑拳,我的命只值3000块
-
2024-06-17 19:23:42
-
- 锦子会教程UI设计初学者应该怎样入门?
-
2024-06-17 19:21:26
-

- 分享9本和端午节有关的绘本,可以让孩子多多了解我们的传统节日
-
2024-06-17 19:19:10
-

- 命运蝶变下的新英雄史诗
-
2024-06-17 18:23:00
-

- 空战进入喷气时代:纳粹Me262战机战史
-
2024-06-17 18:20:44
-

- 中国各城市市花,都在这里了,看看你所在的城市是什么花吧!
-
2024-06-17 18:18:28
-
- “叶赫老女”改嫁与明朝无关,努尔哈赤因政治原因将其列入七大恨
-
2024-06-17 18:16:13
-

- 新势力挖人偷技术,吉利胜诉获赔6.4亿,给谁敲响警钟?
-
2024-06-16 23:42:14
-
- 大模型,真的是教育行业的救赎吗?
-
2024-06-16 23:39:58
-
- 雷军太难了!比亚迪踩过的坑,小米汽车还是躲不过
-
2024-06-16 23:37:42
-

- 第一批人机恋的“AI前任”已经死了
-
2024-06-16 23:35:26
-

- AI视频翻车频发,Luma与Stable Diffusion遭吐槽
-
2024-06-16 23:33:09
-

- 当AI与数学同时走下神坛
-
2024-06-16 23:30:53
-

- 又花 7 亿买公司,张一鸣再战AI硬件
-
2024-06-16 23:28:36
-
- “蔚小理”的中场战役:反击合资、打响智驾之争
-
2024-06-16 23:26:20
-
- 618:带货短剧,阿里VS拼多多的新战场
-
2024-06-16 23:24:04
-

- 特斯拉最强产品将入华?这个大反转,我心脏受不了了
-
2024-06-16 23:21:47
 贵州两落马女厅官出镜忏悔:一人想念父母做的菜;一人带衣服投案
贵州两落马女厅官出镜忏悔:一人想念父母做的菜;一人带衣服投案 山西省晋城市公交线路一览表
山西省晋城市公交线路一览表 我国首位亿万富翁牟其中:3度入狱,小姨子为他守了铁窗16年
我国首位亿万富翁牟其中:3度入狱,小姨子为他守了铁窗16年 河北省泊头市概况
河北省泊头市概况 山东徐氏字辈整理汇编
山东徐氏字辈整理汇编 从广东网友留言看,原民办代课教师补助确实发了,没领的原因分析
从广东网友留言看,原民办代课教师补助确实发了,没领的原因分析 宣化炮院,曾是炮兵最高学府 延安精神传承至宣化,至今已有65年
宣化炮院,曾是炮兵最高学府 延安精神传承至宣化,至今已有65年 普京的秘密情人卡巴耶娃:未婚连生3子,两人绯闻是真的吗?
普京的秘密情人卡巴耶娃:未婚连生3子,两人绯闻是真的吗? 广东省湛江市的六所高校排名,广东海洋大学名气最大
广东省湛江市的六所高校排名,广东海洋大学名气最大