

Sora启示录:信仰、对抗与未来
Sora启示录:信仰、对抗与未来

图片来源 @视觉中国
文 | 硅基研究室,作者 | 山核桃
随着 OpenAI 正式发布首个文生视频大模型 Sora,过去几天里围绕 Sora 技术配方的猜测,对行业影响的讨论成为了科技圈的头条。一位 AI 创业者对 Sora 评价是:" 没有想到文生视频的 GPT 时刻能来的这么快。"
从创业者和行业观察角度,文生视频一直被视为多模态 AIGC「圣杯」,除了本身相较于文生图来说难度更高外,在数据质量、算力以及多融合技术的复杂性上都有诸多需要突破的关卡,这也是为什么即便是行业异常火热,从 Runway 等 AI 视频初创公司崛起,再到去年 Pika 爆火,业内人士也乐观地认为 2024 是 AI 行业的「视频大年」,但还是在时间上留了保守态度。比如,Pika 联合创始人 Chenlin Meng 在去年接受采访预测:" 目前视频生成处于类似 GPT-2 的时刻。"
但 Sora 所呈现的效果还是打破了业内人士的预期。
无论是同行们——马斯克「人类愿赌服输」,Runway 联合创始人「game on」的感慨,还是技术层面,如前阿里总裁贾扬清「非常牛」的评价,似乎让人们一夜之间又回到了一年多前令人恐惧和焦虑的 GPT-3 时刻。
在各类观点之外,Sora 崛起究竟能给创业者乃至技术界带来哪些启示?目前国内外文生视频的发展进度又如何?
01 Sora 是 OpenAI 技术路线的又一次验证
「硅基研究室」曾在《Pika 爆火,但 AI 视频还没到「GPT 时刻」》一文中系统梳理 AI 生成视频模型背后的技术路线,主要可分为三个阶段——
阶段一为基于 GAN(生成式对抗网络游戏)和 VAE 模型(变分自编码器),可以自回归地形成视频帧,但该技术的局限性在于应用范围窄,生成视频分辨率低,且仅能生成静态、单一的画面;
阶段二为受 GPT3 和 DALLE 启发,行业开始采用 Transformer 架构,出现了谷歌的 Phenaki、微软的 NUWA 等一系列的视频生成模型,巨头押注之中,提升了视频模型的能力,例如可以捕捉上下文,实现颗粒度更细的语义控制等,却缺点也更明显了——计算量太大了,对配对数据集的要求也更大。
阶段三也则是受 stable diffusion 等文生图应用扩散模型的启发(diffusion models),从图像到视频领域,采用扩散架构成为了主流,Meta 的 Make-a-video、英伟达的 Video LDM,初创公司 Runway 的 Runway-Gen1、Runway-Gen2、字节的 MagicVideo 等也都是采用了扩散架构。
但扩散模型这一技术路线在算法、数据上存在难点,比如如何改善计算成本和提升数据集质量这一老问题,以及在生成效果与质量上,例如画面的一致性、分辨率、生成长度上也有不少的问题。
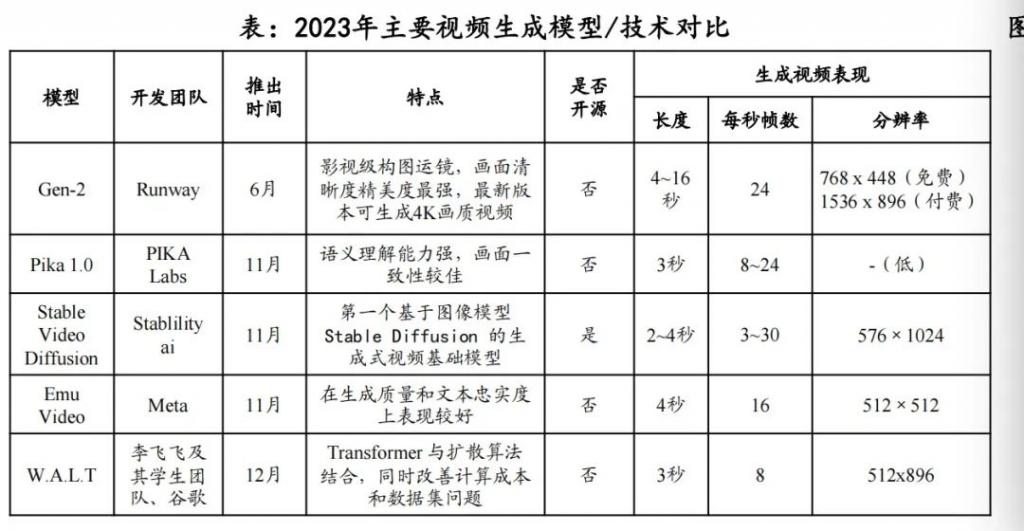
图片来源:东吴证券
而 Sora 所呈现出的效果,如生成风格的多样性、画面的一致性等优势恰好弥补了过去视频生成模型的劣势。而复盘 Sora 之所以能加速视频模型进程,综合官方的技术文档和专家的猜测观点,核心逻辑依旧是 OpenAI 技术路线的又一次验证,这套路线的特点是:大力出奇迹、足够简洁和坚守技术信仰。
一是大力出奇迹,Sora 遵循了 OpenAI 推崇的 Scaling Law。在 Scaling Law 的指导下,OpenAI 擅长以更大规模的算力和数据提升模型性能表现。思谋科技创始人贾佳亚评价 Sora:"Sora 是大力出奇迹,在学术界连 VIT 的 256*256 的分辨率都没法改的情况下,Sora 直接用上了高清以及更大的分辨率,这没几千上万张 H100 都不敢想象如何开始这个项目。"
二是简洁性。根据技术文档和专家猜测,Sora 是使用了混合模型架构——是 Transformer 架构的 Diffusion 扩散模型,据纽约大学数据科学中心的助理教授谢赛宁的猜测(注:他也是 Sora 技术文档中所引用的一篇关键论文的作者之一),Sora 应该是建立在一种混合模型 DiT 之上(DiT 是一个带有 Transformer 主干的扩散模型,它 = [ VAE 编码器 +ViT+DDPM+VAE 解码器 ] )。
同时,Sora 参考了文生文模型中的 Token 原理。在文生文模型中,文本被同意转化为 token 的数字表示形式,用以模型训练。而 OpenAI 提出了一种用 patch(视觉补丁)统一图像与视频的方法。

OpenAI 官方公布的示例视频
谢赛宁就评价这些技术特点是「简单性和可扩展性」,没有专注于创新。" 因为简单性意味着灵活性。"
三是不变的技术信仰。Sora 的爆发并非是短期,而是源自业界(比如老大哥谷歌)的技术尝试以及 OpenAI 长期的技术积累,从文本、图像等诸多技术尝试中均可见一斑。
创新无法被计划,但所有的创新都可以成为颠覆式创新的垫脚石,这仍然是 OpenAI 给大公司留下的启示。
02 与 Sora 的距离有多远?
不可否认的是,在「太牛了」等感叹后,国内外的大模型企业也开始了新一轮的焦虑:从文本、图像再到视频模型,随着差距进一步拉大,「追赶」又成了新一轮的主题。
去年 Pika 爆火时,行业曾预测,未来在视频领域也会是一家公司领先一到两年,其他公司在追赶。但现在,竞争的时间窗口正因 Sora 而大大缩小。面对与 OpenAI 的竞争,Pika 创始人郭文景回应:" 我们觉得这是一个很振奋人心的消息,我们已经在筹备直接冲,将直接对标 Sora。"
根据美国 VC 机构 a16z 的统计,2023 年,文生视频领域发布相关工具与产品达到了 21 种,发布产品的多为初创企业。
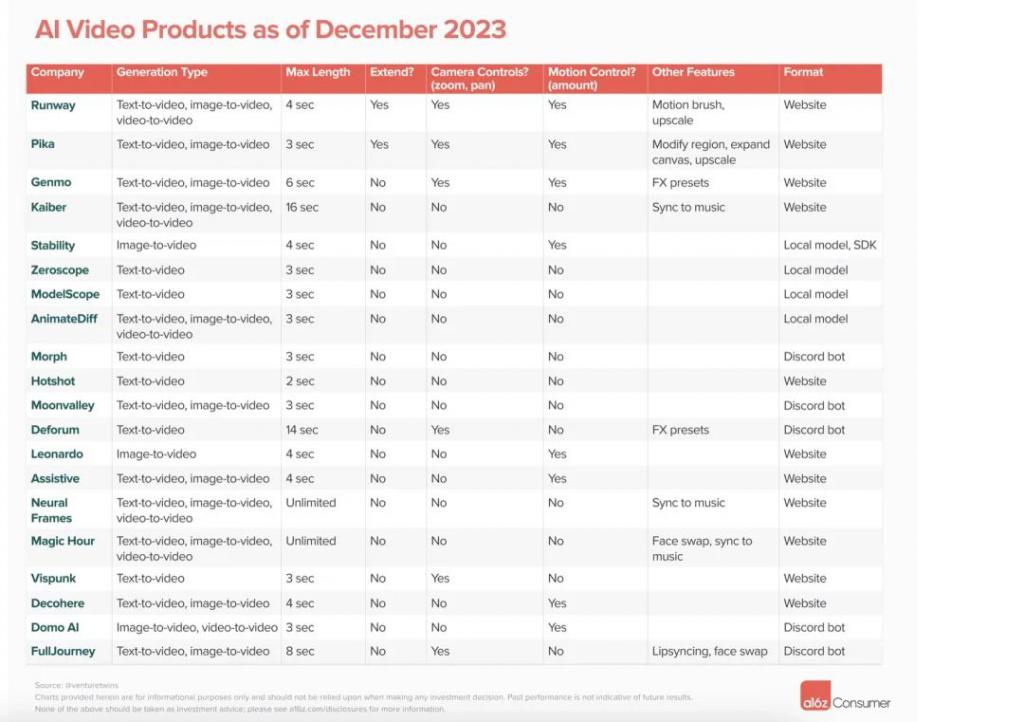
图片来源:a16z
但当前,国内国外的文生视频领域呈现出不同的竞争态势。
在国外,一方面形成了「科技巨头 + 创业派 + 专业派」的组合,目前头部科技巨头基本都已入局,只是产品尚未全面公测。专业派则是如 Adobe 此类面向专业级用户的老牌软件巨头。而创业派则是包括了 Runway、Pika 等。另一方面,由于海外较为细分和垂直化的科技生态,也涌现出如 HeyGen、Descript、Rephrase.ai 等围绕轻量化视频制作的工具或平台型企业,这一部分初创企业目前也在通过收购或被收购,扩充生态。比如 OpenAI 参投了 Descript,而 Rephrase.ai 则被 Adobe 收购。
反观国内,目前的路线和竞争格局还尚不清晰。「硅基研究室」梳理,大厂也在积极押注视频生成,如字节跳动的文生视频模型 MagicVideo-V2、阿达摩院的 Zeroscope 等。不久前,张楠辞任抖音集团 CEO,同时转向剪映发展,也被外界解读为字节对视频领域押注。
尽管技术水平不同,生态也不同,但摆在国内外企业面前的难点与挑战也是类似的。
首先在技术方面,由于是闭源模型,Sora 并未公开更多的技术细节,路径依旧是模糊的。据魔搭社区开发者的讨论,一些可能的技术难点如下:Sora 究竟是如何保证视频特征被更好地保留的?Sora 的数据集组成如何?如何保证海量高质量的数据(数据的获取和标注又是如何完成的?)
其次在算力方面,初创企业难以复刻 OpenAI「大力出奇迹」的路径,奥特曼近期一系列押注算力的计划也再度印证了算力的稀缺性。随着大模型的发展速度更快,算力成本是否能如奥特曼所想的那样降低,二者之间谁的速度更快,这一速度线往往就是初创企业的生死线。
尽管焦虑,但并非没有路可走。如一位开发者所言:"OpenAI 画了一条「模糊」的路,但有了这条模糊的路,大家就可以去尝试,从而画出通往视频生成的正确的清晰的路。"
南洋理工大学研究工程师周弈帆就认为从技术贡献上来看,Sora 其中一项创新就是使用了一种不限制输入形状的 DiT。"DiT 能支持不同形状的输入,大概率是因为它以视频的 3D 位置生成位置编码,打破了一维编码的分辨率限制。后续大家或许会逐渐从 U-Net 转向 DiT 来建模扩散模型的去噪模型。"(注:UNet 是一种流行的卷积神经网络架构,特别适合图像分割任务)
而对一些内容创作者而言,他们关心的不仅是技术,也有开源问题。实验电影人、AIGC 艺术家 @海辛在即刻中写道:"我还是更相信开源社区,OpenAI 总是提供很好的范式,DallE2,GPT,Sora.. 但至今你都没办法让 DallE2 画具体某个游戏画风的角色 / 场景,由于数据集本身的多样性不够,导致没有办法做具体的项目风格,风格没有办法自定义,对于大多数商业项目来说就没有意义,即实用性很低。"
如人们所预测的 2024,无疑是 AI 视频大年,Sora 提供了一种新的技术路线和方向,也为内容创作者提供了新的工具,新的追赶开始了,新的竞争与创意也从此刻开始,也正在发生。
参考资料:
1、魔搭社区:复刻 Sora 有多难?一张图带你读懂 Sora 的技术路径
2、Hugging Face:文生视频 : 任务、挑战及现状
3、未尽研究:Sora 模型只有 3B
4、国盛证券:AI 文生视频:多模态应用的下一站
5、东吴证券:多模态技术加速,AI 商业宏图正启
6、天才程序员周弈帆:OpenAI 视频模型 Sora 科研贡献速览
7、甲子光年:Sora 涌现,OpenAI 又一次暴力美学的胜利
-

- 7000亿,孙正义正式宣战
-
2024-02-20 02:51:25
-

- 拼多多海外“历劫”,谁在限制Temu的想象力?
-
2024-02-20 02:49:09
-

- 日本“驸马”升职记
-
2024-02-20 02:46:53
-

- 中产,开始懂得“日日是好日”
-
2024-02-20 02:44:37
-

- 《热辣滚烫》:见证一个“女版吴京”的诞生
-
2024-02-20 02:42:22
-

- 中国13万亿大省,奔向新“科学的春天”
-
2024-02-20 02:40:06
-

- 做梦梦见和朋友吵架什么意思 梦见与朋友吵架是什么意思
-
2024-02-18 23:50:46
-

- 冷藏车分类标准是什么意思啊 冷藏车分类标准是什么意思图片
-
2024-02-18 23:48:31
-

- 望穿秋水是什么意思 望穿秋水是什么意思 百度网盘
-
2024-02-18 23:46:15
-

- 不吃早餐的8大危害是什么呢 不吃早餐的8大危害是什么意思
-
2024-02-18 23:43:59
-

- 康乃馨代表什么意思 向日葵的寓意是什么意思
-
2024-02-18 23:41:43
-

- KFC是美国哪儿的炸鸡?KFC三个字母分别是什么意思?
-
2024-02-18 23:39:28
-

- dr是什么意思dr Dr是什么意思的缩写
-
2024-02-18 23:37:12
-

- 省控线和本科一批的区别大吗河南 本科一批和本科省控线是什么意思
-
2024-02-18 23:34:56
-

- 女人梦见找不到回家的路了是什么意思 梦见找不到回家的路了是什么意思,路上有
-
2024-02-18 23:32:41
-

- 望眼欲穿是什么意思解释词语 望眼欲穿是什么意思呢
-
2024-02-18 23:30:24
-
- 体检报告箭头向下 体检报告箭头向上是什么意思
-
2024-02-18 03:16:00
-
- 肝功能十八项指的什么意思 肝功能十八项指的什么项目
-
2024-02-18 03:13:45
-

- 大金猪什么意思 大金猪是什么
-
2024-02-18 03:11:29
-

- 炒股:XD股是什么意思?股票“XD”时应该买入还是卖出?
-
2024-02-18 03:09:13
 苹果Vision Pro,被华强北啃了
苹果Vision Pro,被华强北啃了 北京等地上空疑现不明飞行物!目击网友称“飞着飞着就没了”
北京等地上空疑现不明飞行物!目击网友称“飞着飞着就没了” 2831人考试2093人次替考!广州开放大学分管副校长解聘
2831人考试2093人次替考!广州开放大学分管副校长解聘 毛戈平7年IPO折戟,国货化妆品的出路在哪里
毛戈平7年IPO折戟,国货化妆品的出路在哪里 荣耀赵明:Magic6要在体验上超越iPhone而不是参数上
荣耀赵明:Magic6要在体验上超越iPhone而不是参数上 大模型浪潮不能使鬼推磨,但可以让周鸿祎、傅盛握手言和
大模型浪潮不能使鬼推磨,但可以让周鸿祎、傅盛握手言和 不想过年的年轻人,躲回工作中
不想过年的年轻人,躲回工作中 中产捧红的始祖鸟即将IPO,安踏捧出第二个“FILA”?
中产捧红的始祖鸟即将IPO,安踏捧出第二个“FILA”? 嘉行传媒还“行”不“行”?
嘉行传媒还“行”不“行”? 张学良故居在什么位置 张学良故居在哪里
张学良故居在什么位置 张学良故居在哪里